xAI正式向所有用戶推出Grok 4.1模型,可透過grok.com、𝕏平台及iOS和Android應用程式,重點改善資訊查詢的準確度問題。新模型在創意互動、情感理解及協作能力方面有顯著提升,同時保留前代的智能水平及可靠性。開發團隊採用大規模強化學習技術,並首次運用最新推理模型作為獎勵模型,自動評估及改進回應質素。
在LMArena的Text Arena盲測中,Grok 4.1 Thinking模式以1483分Elo評分排名第一,比最高分非xAI模型高出31分。即使不使用推理模式的Grok 4.1也取得1465分,超越所有其他模型的完整推理版本。相比之下,前代Grok 4僅排名第33位。
情感智能測試EQ-Bench3評估模型的情感理解、同理心及人際技巧,包括45個複雜角色扮演場景。Grok 4.1 Thinking在此測試中取得1586分標準化Elo評分位居榜首,非推理版本也有1585分排名第二。創意寫作基準Creative Writing v3方面,Grok 4.1 Thinking獲得1721.9分排名第二,僅次於GPT 5.1的早期版本。
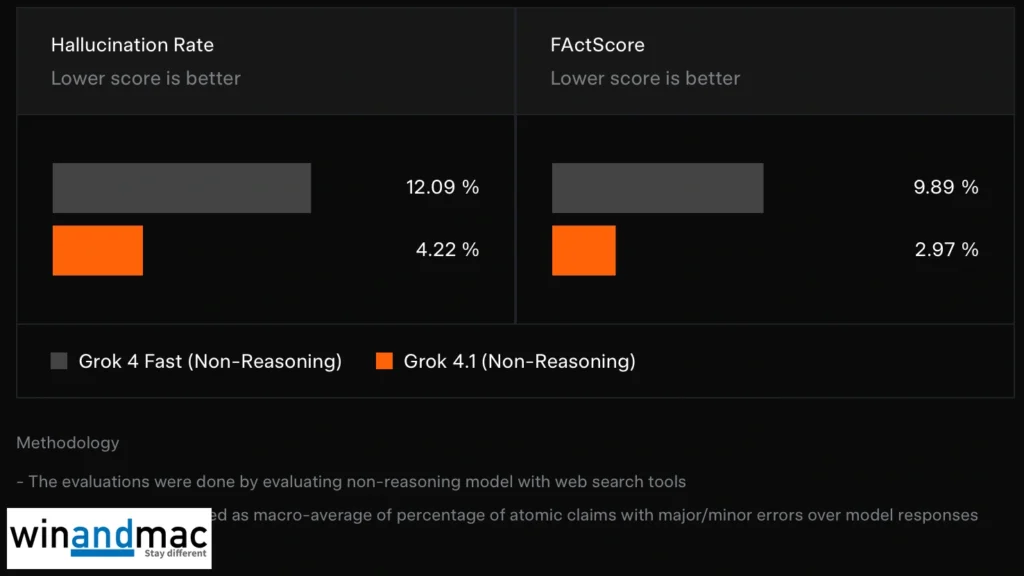
準確度方面,Grok 4.1針對真實資訊查詢大幅降低幻覺錯誤率。在FActScore的500個人物傳記問題測試中,新模型的錯誤率明顯低於前代Grok 4 Fast。xAI表示改進來自訓練過程中專注減少事實性錯誤,並在有限工具調用預算下提升推理深度。