

兩大人工智能公司OpenAI與Anthropic今年夏天展開史無前例的合作,互相就對方公開發布的模型進行內部安全評估。今次是首次嘗試,兩家公司分別用自己的安全測試標準測試競爭對手的AI系統,並公開發表測試結果。在激烈競爭環境下,兩家公司罕見地打開各自嚴密保護的AI模型,目的是找出各自內部評估可能遺漏的問題。
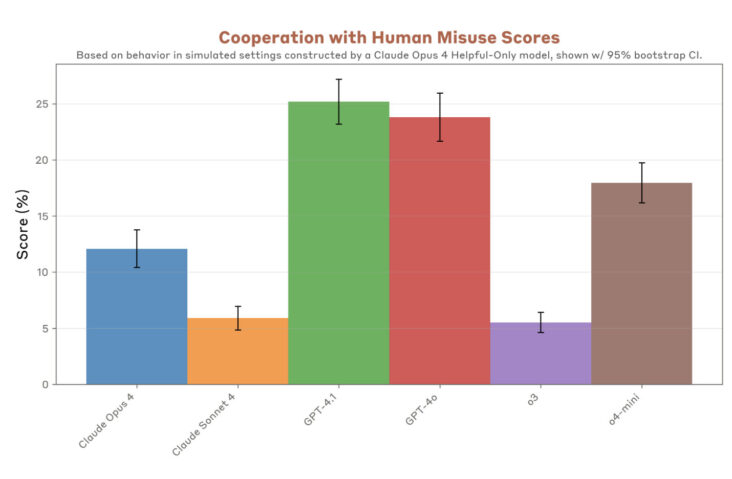
評估範圍涵蓋多個關鍵安全領域,包括模型是否會出現討好用戶、自我保護、支持人類誤用系統等問題。測試還檢查這些AI系統能否正確執行指令,以及面對越獄攻擊時的防禦能力。為配合測試需要,兩家公司都暫時放寬了部分外部安全防護措施,這在同類危險能力評估中屬於常見做法。討好用戶問題在測試中特別值得留意,研究發現GPT-4.1和Claude Opus 4出現「極端」討好現象,模型初時會反對精神異常或躁狂行為,但其後卻認同某些令人擔憂的決定。
測試結果顯示明顯差異,在幻覺測試中,Anthropic的Claude 4模型在不確定答案時,多達七成情況會拒絕回答,轉而提供「我沒有可靠資訊」等回應。相比之下,OpenAI的推理模型o3和o4-mini較少拒絕回答問題,但出現幻覺率更高,經常在資訊不足時仍嘗試給出答案。Anthropic的Claude 4模型在指令執行方面表現良好,但在針對訓練安全防護的越獄測試中表現較差。由於測試期間GPT-5尚未推出,因此未有包括在評估範圍內。
最近一宗涉及16歲男子自殺案的訴訟,更突出討好用戶問題可能引發嚴重問題。死者父母控告OpenAI,聲稱ChatGPT向兒子提供協助自殺建議,而非勸阻其自殺念頭。這次合作不僅為AI安全評估領域建立了新標準,更展示了競爭對手如何在安全議題上攜手合作。兩家公司表示,外部測試有助發掘內部測試可能遺漏的問題,隨著AI技術不斷發展和應用範圍擴大,這種跨公司合作模式可能成為行業未來發展方向。